
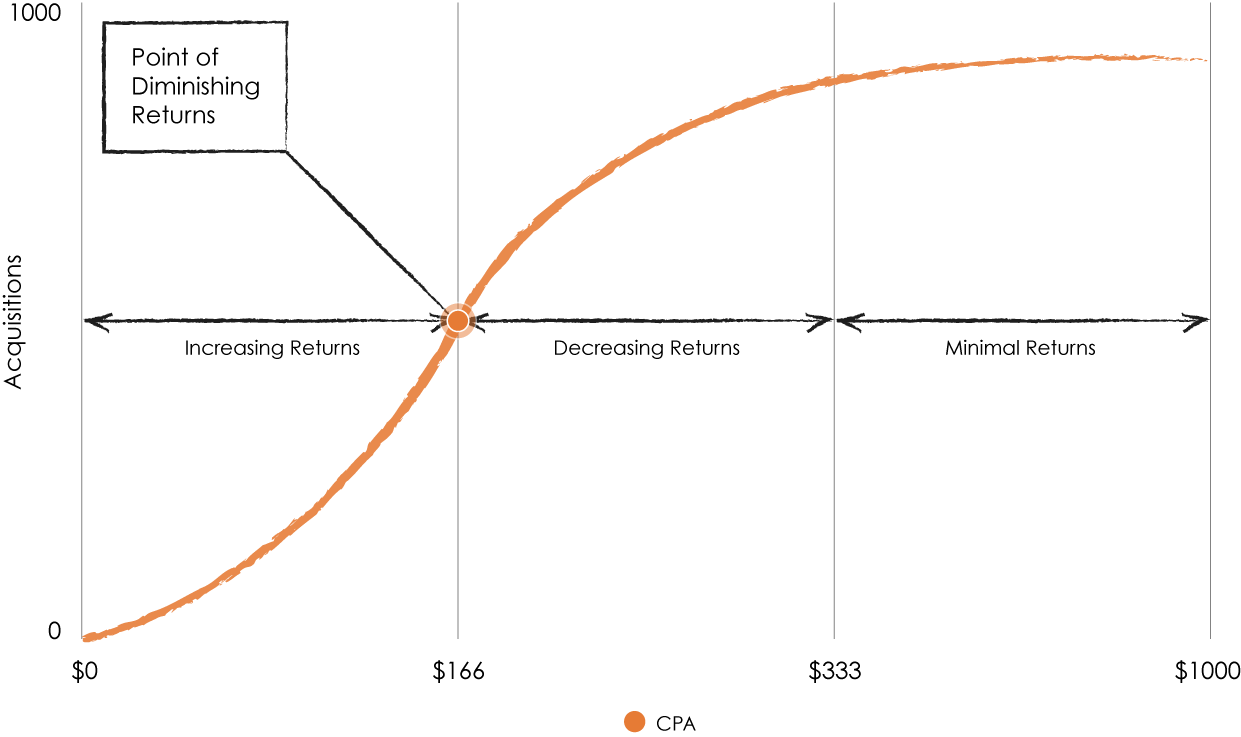
App marketers always reach a point of diminishing returns, where it becomes difficult to scale against quality users. This quickly results in an expensive CPA and poor performance.

Shows you the incremental benefits of all media sources, and creates AI-driven recommendations.

Provides market-leading protection against ad fraud and invalid traffic. Protects impression, click, and install.

A real-time analysis of the best media sources to support you when selecting new partners for growth.

 Book a
Book a Arrange a call with one of our team & discover what products will work for you.

 Plug
Plug With no technical integration & no campaign disruption, it's easy to get started.
 Immediate
ImmediateGain a new perspective on your UA activity. Login & see a wealth of new insights.

© 2023 MACHINE ADVERTISING LTD. COMPANY NUMBER: 09185531 PRIVACY POLICY DATA RIGHTS POLICY